RAG Chatbot with Amazon Bedrock & LangChain
Exploring the Potential of Conversational AI with Serverless Foundation Models
Cloud Architect/Engineer with leadership and communication skills. Ownership of the entire lifecycle of a project (SDLC), and motivated to continue growing in Cloud and automation. Passionate about new technologies, responsible and enthusiastic collaborator dedicated to streamline processes and eciently solve project requirements.
Introduction
Large Language Models (LLMs) are revolutionizing how we interact with information, but they face challenges with accuracy and access to up-to-date data. Retrieval Augmented Generation (RAG) addresses these limitations by grounding the LLM's responses in a dedicated knowledge base.
This article explores a project based on the implementation of a RAG chatbot using Amazon Bedrock and LangChain that enhances the chatbot's ability to provide more contextually relevant, and current information, making it a key approach for a wide range of applications based on generative AI. The full codebase of the project is available in my GitHub repository.
Design considerations
As can be seen in other articles of my Blog, I usually review the design considerations of any project, workload or cloud architecture showcase in order to provide more wide vision about the main purpose of it. For this case, the following design principles guided the development:
Serverless LLM Architecture : Leveraging Amazon Bedrock's serverless infrastructure eliminates the need for managing infrastructure, simplifying deployment, scaling, and experimentation. This allows developers to focus on building the core logic of the chatbot without worrying about server management.
Modularity: The codebase is designed with modularity in mind, facilitating easy extension, component swapping, and simplified maintenance as the project evolves. This approach promotes code reusability and makes it easier to integrate new features or adapt to changing requirements.
Streamlit for Rapid Prototyping: Streamlit's intuitive framework allows for rapid prototyping and development of user interfaces.
Dockerized Deployment: The project is containerized using Docker, ensuring consistent execution across different environments and simplifying deployment to various platforms.
Extensibility: The design allows for easy integration with different data sources and future enhancements like personalized responses or multi-modal search.
Cost-Effectiveness: While not fully optimized for production, cost-effective practices are considered, such as choosing appropriate model sizes and efficient data handling. This helps keep experimentation costs manageable and lays the groundwork for future optimization in a production environment.
Architecture
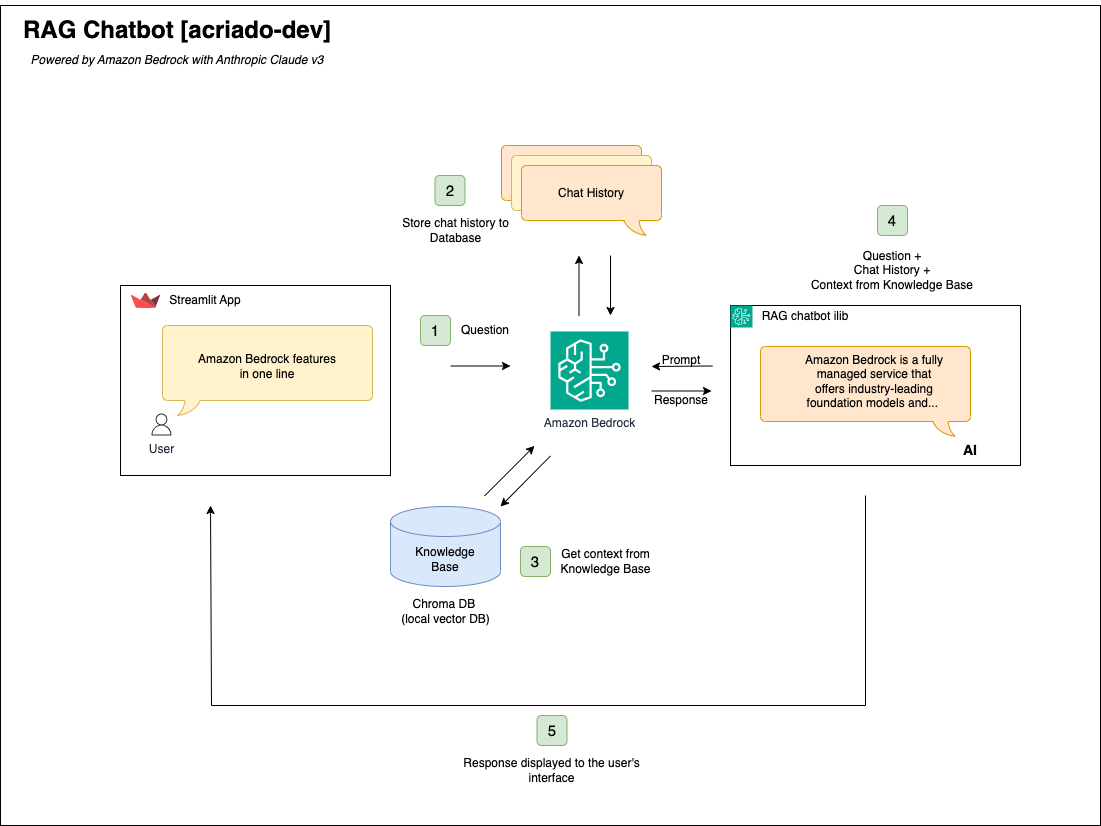
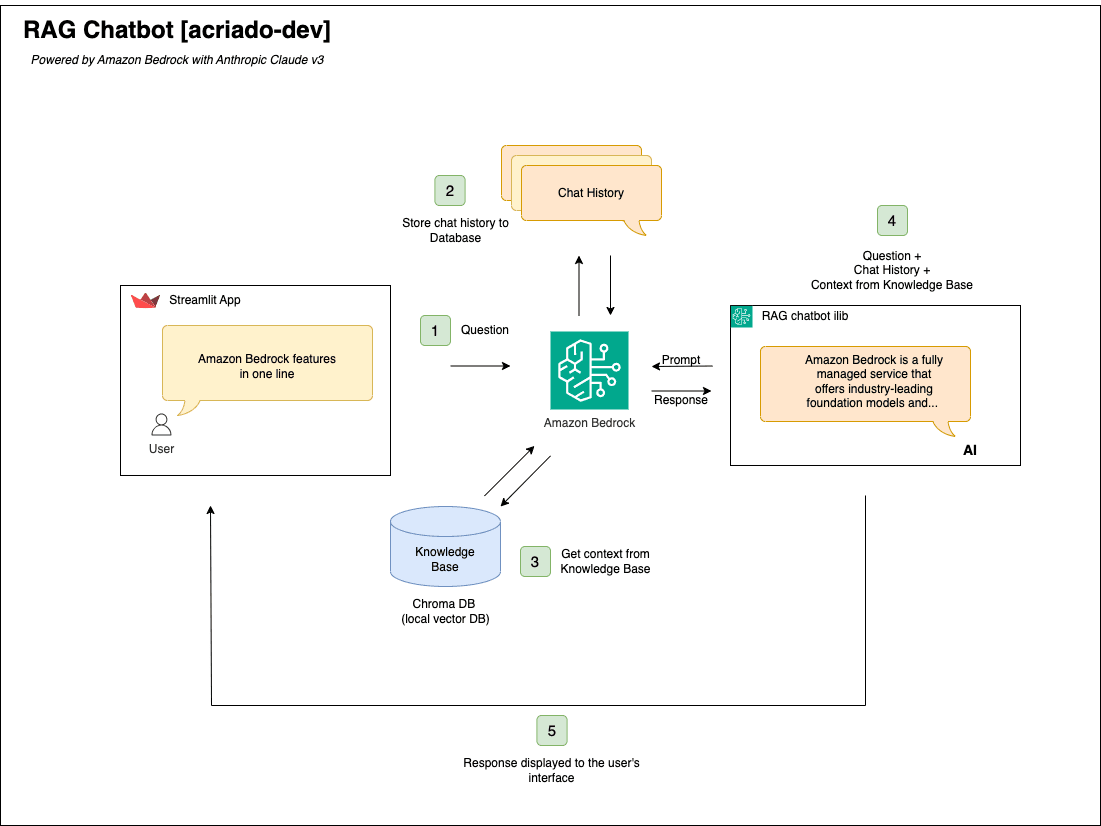
Key Components
Knowledge Base: Designed to be flexible, can ingest data from various sources, including CSV files, potentially expanding to databases and other formats in future iterations.
Vector Database (ChromaDB): Stores vector embeddings of the knowledge base generated using a suitable embedding model like
amazon.titan-embed-text-v2:0. This allows for efficient similarity searches when retrieving relevant information.Streamlit: Provides the user interface for interacting with the chatbot. Streamlit's intuitive API and interactive components make it easy to build a user-friendly interface for querying the knowledge base and visualizing responses.
Amazon Bedrock: Provides access to the foundation models powering the chatbot. Specifically,
amazon.titan-embed-text-v2:0is used for creating text embeddings, whileanthropic.claude-3-sonnet-20240229-v1:0is employed for text generation and driving the conversational aspect of the application. Bedrock's serverless infrastructure simplifies deployment and experimentation with these powerful models.LangChain: Orchestrates the interaction between the vector database, LLM, and user interface. It streamlines the development process and manages the retrieval and generation workflow.
Workflow
- Data Preprocessing
The user enters a new question in the Streamlit Chat App.
The Chat history is retrieved from memory object and added prior the new message entered.
The question is converted to a vector using Amazon Titan Embeddings, then matched to the closests vector in the database to retireve context.
The combination of new Question received, Chat history, and Context from the Knowledge base are sent to the model.
The model's response is displayed to the user in the StreamLit App.
Data Preprocessing
A critical preprocessing step prepares the data for efficient retrieval and influences the quality of the chatbot's responses. This involves structuring the data and generating embeddings for each piece of information.
The data is organized in a JSON file containing an array of objects. Each object represents a chunk of information and has the following structure, illustrated by this example of Amazon Bedrock Faqs that has been ingested:
{
"id": 1,
"document": "What is Amazon Bedrock?\\nAmazon Bedrock is a fully managed service...",
"metadata": {
"topic": "bedrock"
},
"embedding": [-0.1018051, 0.01927839, 0.004059858, ...]
}
"id": A unique integer ID for each text chunk."document": The raw text content of the chunk, which includes questions like "What is Amazon Bedrock?" and their corresponding answers. Notice the\\nindicating newline characters within the text."metadata": Currently, metadata includes a "topic" field set to "bedrock", suggesting this data relates to information about Amazon Bedrock. This could be expanded to include other relevant metadata like source or date."embedding": A 768-dimensional vector representing the semantic meaning of the "document". These embeddings are pre-calculated using theamazon.titan-embed-text-v2:0model, which supports a flexible embedding dimension size, and are crucial for efficient similarity search within the vector database. Storing them directly in the JSON avoids recalculation during query time, significantly improving performance.
This embedding strategy, coupled with the structured JSON format, optimizes retrieval efficiency and allows the chatbot to generate more relevant and contextually appropriate responses.
Conclusion
This RAG chatbot prototype provides a solid starting point for developers looking to explore and experiment with retrieval augmented generation. By combining Amazon Bedrock, Pinecone, and LangChain, we can build intelligent conversational AI systems that are more grounded and informative. The project demonstrates the potential of RAG for building a new generation of conversational applications.
Next Steps
The mentioned GitHub repository amazon-bedrock-rag-chatbot contains the complete code and instructions for running the project in local environment. Looking forward, next feature development could focus on:
Expanding data ingestion capabilities: Supporting more diverse data sources and formats.
Improving retrieval accuracy: Experimenting with different retrieval strategies and ranking algorithms.
Exploring advanced features: Adding personalization, multi-modal search, and more sophisticated user interfaces.
![[Lab] AWS Lambda LLRT vs Node.js](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1715799253631%2F9f12f208-484e-499e-9324-ec4f37855660.png&w=3840&q=75)